中國仙氣女子在找魚,一個外星的飛艇正躲在海底
本地電腦GDU4060AI win2.1和hunyuan 和FLUX 跑


本文主要介绍如何在Windows系统电脑本地部署ComfyUI并接入通义万相Wan2.1模型,轻松实现使用文字指令生成AI视频,结合cpolar内网穿透工具还能远程在线使用,无需公网IP也不用准备云服务器那么麻烦。
最近,阿里发布了最新的视频生成开源AI大模型——Wan 2.1。这款模型不仅完全免费,还能在普通的家用级配置电脑上离线运行,生成效果媲美目前大多数开源模型的视频质量。其综合实力在VBench榜单上得到了充分验证,甚至一些闭源模型也难以望其项背。
无论你是想用文字生成视频,还是将图片转化为动态画面,Wan 2.1都能轻松搞定。普通用户也能快速上手,体验AI视频生成的乐趣。除了使用体验非常棒,它的本地部署流程也非常简单,下面就来详细介绍一下如何在本地快速安装并使用它来生成AI视频。
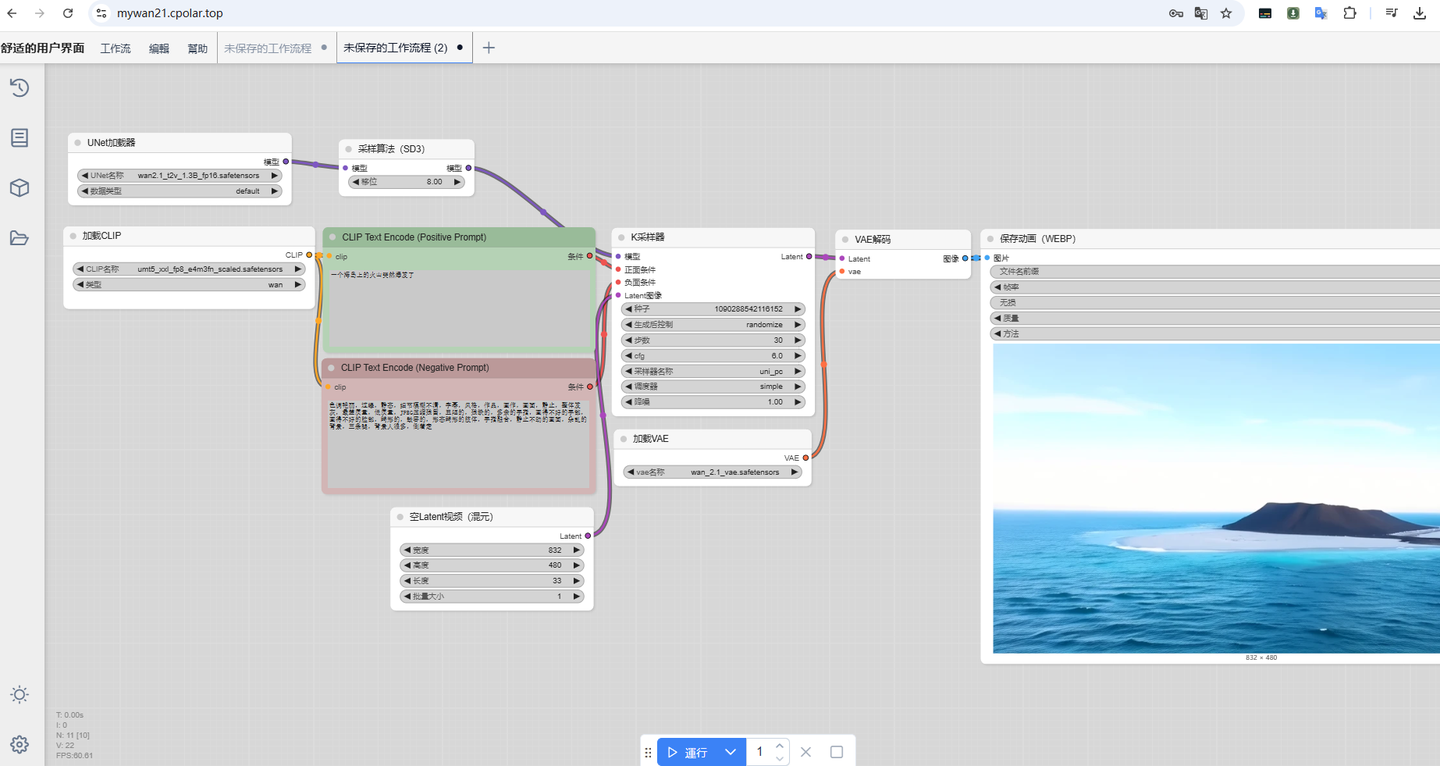
1.软件准备
1.1 ComfyUI
下载 ComfyUI 一键安装包 :【点击前往 】,支持 Windows 和 mac 系统
Wan 2.1 视频生成模型本地部署:
文字转视频
1、下载 ComfyUI 一键安装包 :【点击前往 】,支持 Windows 和 mac 系统
2、下载文本编码器和 VAE :umt5_xxl_fp8_e4m3fn_scaled.safetensors 或【网盘下载】,下载后放入:ComfyUI/models/text_encoders/ wan_2.1_vae.safetensors 或备用【网盘下载】 下载后放入:ComfyUI/models/vae/
注意:建议使用 fp16 版本而不是 bf16 版本,因为它们会产生更好的结果。
质量等级(从高到低):fp16 > bf16 > fp8_scaled > fp8_e4m3fn
这些文件位于:ComfyUI/models/diffusion_models/
这些示例使用 16 位文件,但如果内存不足,则可以使用 fp8 文件。
4、文字转视频工作流:下载 Json 格式的工作流
进阶篇: 图像转视频
此工作流程需要wan2.1_i2v_480p_14B_fp16.safetensors文件(将其放入:ComfyUI/models/diffusion_models/)和 clip_vision_h.safetensors放入:ComfyUI/models/clip_vision/
请注意,此示例仅生成 512×512 的 33 帧,因为我希望它易于访问,但模型可以做的不止这些。如果您有硬件/耐心运行它,720p 模型就相当不错。
输入图像可以在通量页面上找到。
以下是720p 型号的相同示例
- 通过ComfyUI管理器安装:点击“管理器”,点击“安装节点”,搜索“ComfyUI-Crystools”,点击“安装”。
————————————————
LTX-Video
Multi Frame Control
Allows you to control the video with a series of images. You can download the input images: starting frame and ending frame.

Image to Video
Allows you to control the video with a first frame image.

Text to Video

Requirements
Download the following models and place them in the locations specified below:
筆電上使用ComfyUI來運行Flux模型
打開網頁後,右上角會新增一個"Manager"藍色按鈕,點擊就會看到ComfyUI Manager Menu

STEP 5 下載Flux模型
由於我使用的是8G VRAM的GPU,如果你有更強大的GPU,可以根據你的GPU的顯存大小(VRAM),選擇差不多大小的Flux模型。例如我使用的是"flux1-schnell-Q5_K_S.gguf",模型大小為8.26GB。
打開ComfyUI Manager介面,點擊Model Manager,搜尋欄輸入"flux1-schnell",會出現眾多版本的模型,不知道選哪一個的話,可以先用"flux1-schnell-Q5_K_S.gguf",點擊Install就會開始自動安裝。

或者也可以直接到city96這位作者的Hugging Face頁面下載GGUF格式的Flux模型:
https://huggingface.co/city96/FLUX.1-schnell-gguf/tree/main

將模型放入\ComfyUI\models\unet目錄即完成。

STEP 6 下載Clip模型
到這個Hugging Face頁面下載以下兩個Clip模型:
- clip_l.safetensors
- t5xxl_fp8_e4m3fn.safetensors
https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main
並將兩個Clip模型放到\ComfyUI\models\clip目錄底下。

STEP 7 下載VAE模型
到Hugging Face頁面下載這個Clip模型:
- ae.safetensors
https://huggingface.co/black-forest-labs/FLUX.1-schnell/tree/main

並將VAE模型放到\ComfyUI\models\vae目錄底下。

STEP 8 安裝 ComfyUI-GGUF 自定義節點
要在ComfyUI中使用GGUF格式的模型,需要安裝 ComfyUI-GGUF 這個自定義節點。這將會為你的ComfyUI新增 UNet Loader (GGUF) 和 DualClip Loader (GGUF) 節點。
打開ComfyUI Manager → 點擊Custom Node Manager → 搜尋欄輸入"GGUF" → 安裝ComfyUI-GGUF

以上安裝作業就完成囉!
開始生成你的第一張 AI 繪圖
回到ComfyUI介面將以下三個節點設定如下圖:
- UNet Loader (GGUF) → 選擇Flux模型
- DualClip Loader (GGUF) → 選擇Clip模型
- Load VAE → 選擇VAE模型
最後在 CLIP Text Encode 節點輸入你的提示詞,按下Queue就開始生成圖片了!

結語
透過這篇教學,相信大家已經成功在自己的筆電上架設好 ComfyUI 和 Flux 的環境了!雖然入門時可能會遇到一些技術障礙,但只要按部就班地完成安裝步驟,人人都能擁有自己的 AI 繪圖工作站!
要使用 GGUF 文件,我们将把 UNet Loader GGUF 和 DualClip Loader GGUF 节点添加到工作流程的开头:
GGUF quantized version of hunyuan-video
calcuis/hunyuan-gguf · Hugging Face
沒有留言:
張貼留言